Pipeline ETL v1.0.0
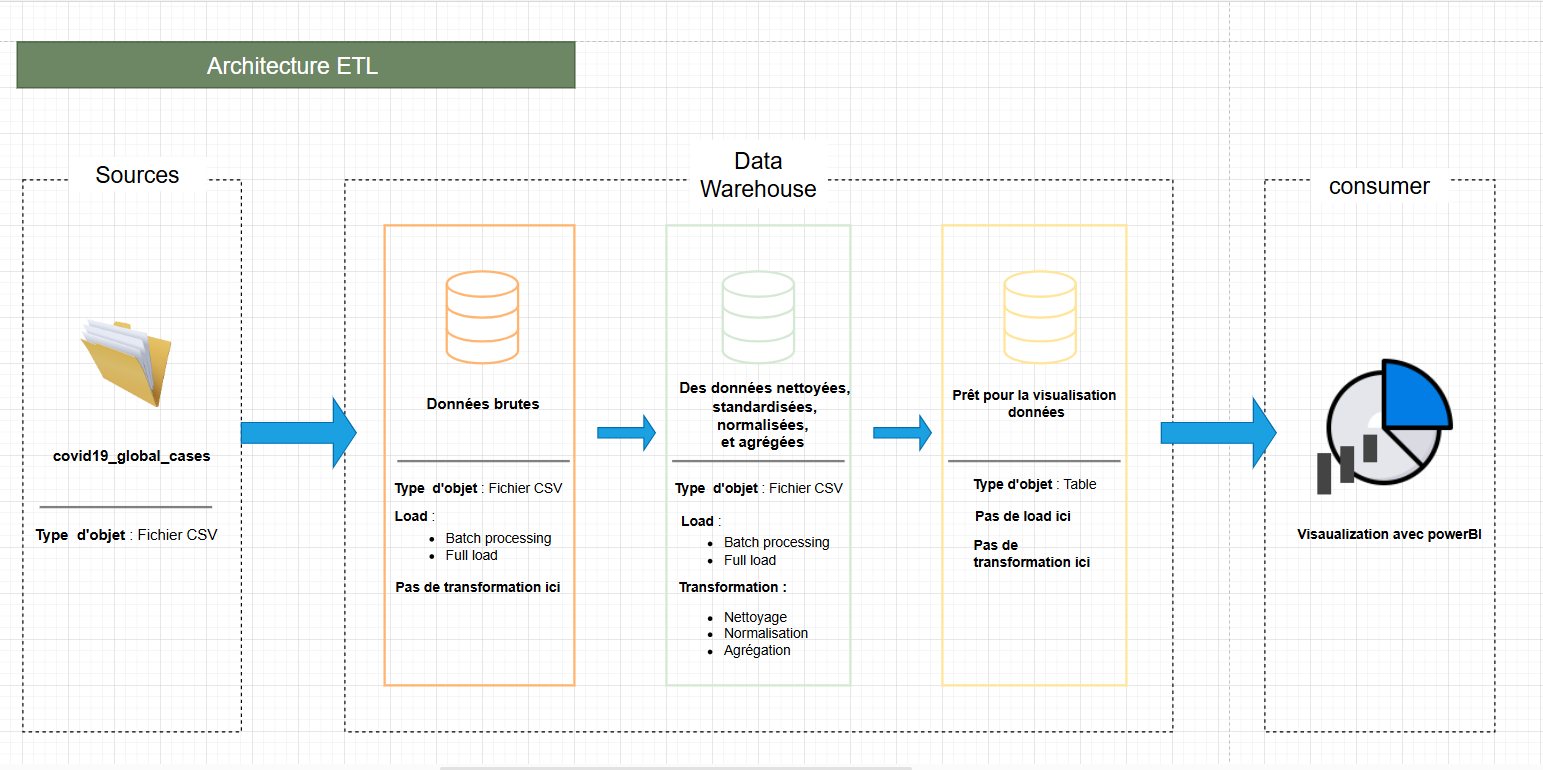
Diagramme du Pipeline ETL
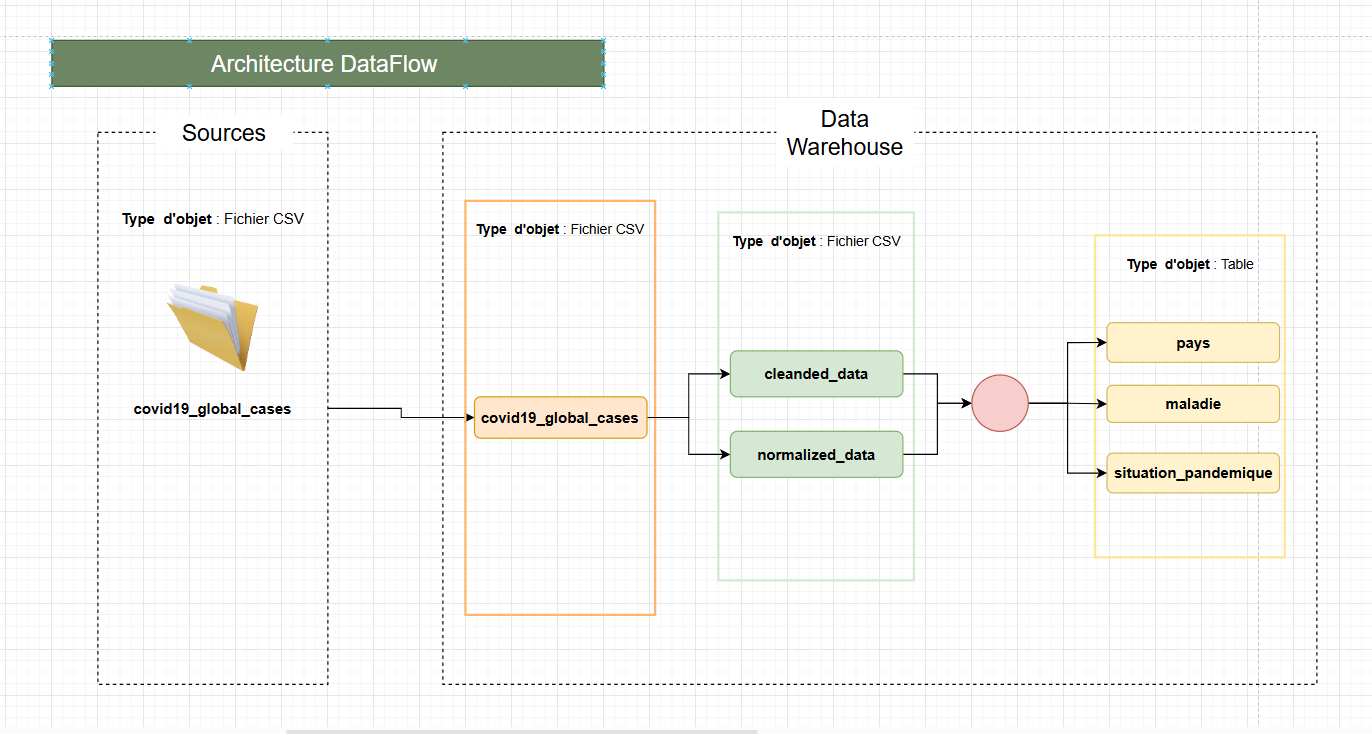
Flux de Données
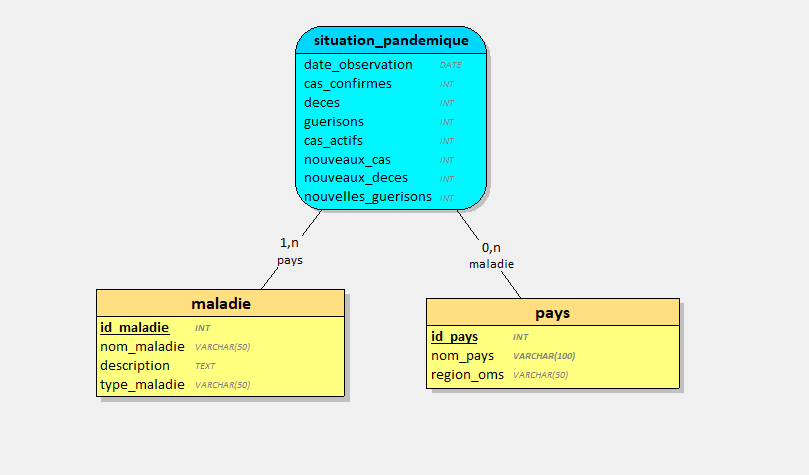
Schéma de la Base de Données, MCD
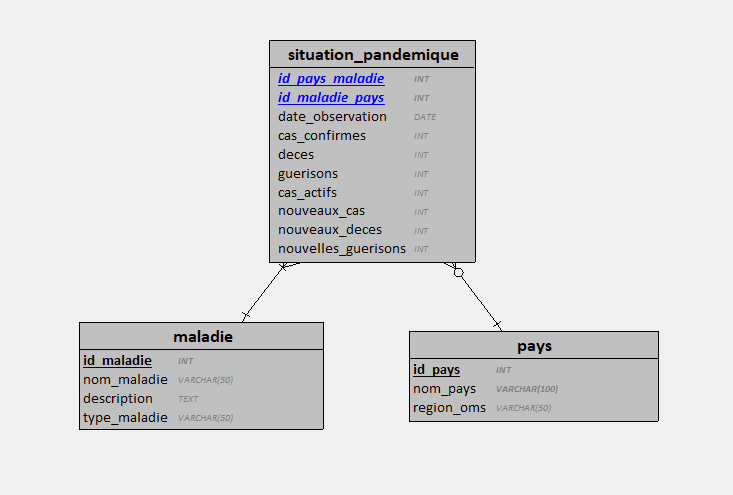
Schéma de la Base de Données, MLD
Description
Dans le cadre de ma formation à l'EPSI Paris, nous avons été amenés à travailler sur un pipeline ETL (Extract, Transform, Load) conçu pour extraire des données de sources variées, les transformer en un format exploitable, et les charger dans une base de données pour analyse. Ce projet se concentre sur l'analyse des données COVID-19 et MPOX.
💡 Analyse et Choix Techniques
Nous avons choisi d'utiliser les données COVID-19 en raison de leur structure bien définie et de leur couverture mondiale, ce qui est essentiel pour notre modèle d'intelligence artificielle.
Stack Technique
- Python pour ETL
- PostgreSQL pour la base de données
- Gestion de version avec GitHub
- SQLAlchemy pour l'ORM
- pandas pour la manipulation des données
- github action pour l'août de l'automatisation des tests
Modélisation des Données
Le modèle de données comprend trois tables principales : pays, maladie, et situation_pandemique. Ces tables sont conçues pour capturer les relations entre les pays, les maladies, et les situations pandémiques.
Défis Techniques Rencontrés
Lors de la mise en place du pipeline ETL, plusieurs défis ont été rencontrés, notamment la gestion des données manquantes et l'optimisation des performances de la base de données.
Solutions Apportées
L'utilisation de bibliothèques Python puissantes comme pandas et NumPy a permis de surmonter ces défis. De plus, l'optimisation des requêtes SQL et l'utilisation d'index ont amélioré les performances.
Autres Problèmes et Solutions
- Problème : Difficulté à suivre les erreurs et les avertissements pendant l'exécution.
- Solution : Mise en place d'un système de logs détaillé pour capturer les erreurs et les événements importants. Utilisation de la bibliothèque
python-json-loggerpour structurer les logs.
- Solution : Mise en place d'un système de logs détaillé pour capturer les erreurs et les événements importants. Utilisation de la bibliothèque
- Problème : Débogage complexe des erreurs dans le code.
- Solution : Utilisation de points d'arrêt (breakpoints) et de l'outil de débogage intégré à l'IDE pour inspecter les variables et le flux d'exécution.
- Problème : Incompatibilité des versions de Python entre les environnements de développement et de production.
- Solution : Utilisation de
pyenvpour gérer les versions de Python et s'assurer que tous les environnements utilisent la même version.
- Solution : Utilisation de
- Problème : Manque de documentation pour les nouveaux développeurs.
- Solution : Création d'une documentation complète avec des exemples de code et des instructions détaillées. Utilisation de
Sphinxpour générer une documentation lisible et bien structurée.
- Solution : Création d'une documentation complète avec des exemples de code et des instructions détaillées. Utilisation de
Processus de Développement
- Création et initialisation du dépôt GitHub
- Configuration de l'environnement virtuel
- Début du développement avec une architecture modulaire
Détails du Projet
Status: En cours
Date: Janvier 2025
Type: Pipeline ETL
Catégorie: Data Engineering
Région cible: Global
Points Forts
- ✅ Architecture modulaire
- ✅ Sécurité des données
- ✅ Automatisation des processus
- ✅ Qualité du code
Technologies Utilisées
- Python
- PostgreSQL
- GitHub
- SQLAlchemy
- pandas